Nyarch Assistant

Nyarch Assistant and Newelle
Nyarch Assistant is a fork of Newelle.
Newelle is available on Flathub and is supposed to be an AI chatbot for Linux users in general, while Nyarch Assistant has some anime and Nyarch Linux-related things that do not make sense for normal users.
Newelle and Nyarch Linux will always be up to date with each other and Newelle extensions will always be compatible with Nyarch Assistant extensions.
Features
-
Your dream waifu, at your command: Choose from a vast library of TTS voices and Live2D or LivePNG models to create the perfect virtual companion.
-
Terminal Command Execution: Execute terminal commands directly through the AI.
-
Advanced Customization: Tailor the application with a wide range of settings.
-
Flexible Model Support: Choose from multiple AI models to fit your specific needs.
-
Extensions support: Add custom LLM, TTS, STT, Avatars, prompts and additional functionalities with minimal python programming
-
Profile Support: Quickly switch totally different settings using our profile functionality
Suggested LLM and models
You are totally free to choose what models and what providers to use Nyarch Assistant with.
By default, Nyarch Assistant uses our Demo API (limited at 10req/day), that uses gemini-flash-2.0 for anything else. These API are just to showcase Nyarch Assistant, you are supposed to use another provider with API Key or use a local model with Ollama or our builtin loader.
If the provider you want is not supported, you can make your own extension or check the existing extensions.
- For general purposes, general knowledge, coding and role playing,
Llama3.1-70B+models are suggested. - If you do more programming/IT things,
qwen3-8b+,deepseek-r1,deepseek-v3,Mixtral8x22B,claude-3.5-sonnetmodels (of basically any size) are preferred. - For roleplay only, you might like
qwen3-4b+,mythomax-l2-13b,llama3.1-7B,gemma3models orwizardlm-2-8x22b.
For more information on how to setup different providers, read Newelle's user guide to LLMs
Nyarch Assistant settings suggestions
Maximum Privacy
With these settings, everything will be run locally and no data about you will be sent anywhere.
Since these computations require a good amount of resources, a good GPU is suggested for good performances.
Local LLMs
Two offline models providers are supported: GPT4All (or "Local Model") and Ollama (Suggested). For instructions on how to setup them, read Newelle Wiki - Local Models. Using a model with Ollama is suggested as it has more fatures and generally better performances. For suggested models, read Suggested LLM and models
TTS
The best supported local TTS with natural sounding voices are Vits and VoiceVox. If you have a nice Nvidia GPU (RTX Series), TTS should be almost instant. In other cases, some loading time might be required.
VoiceVox
VoiceVox is an open source TTS engine really natural sounding for Japanese.
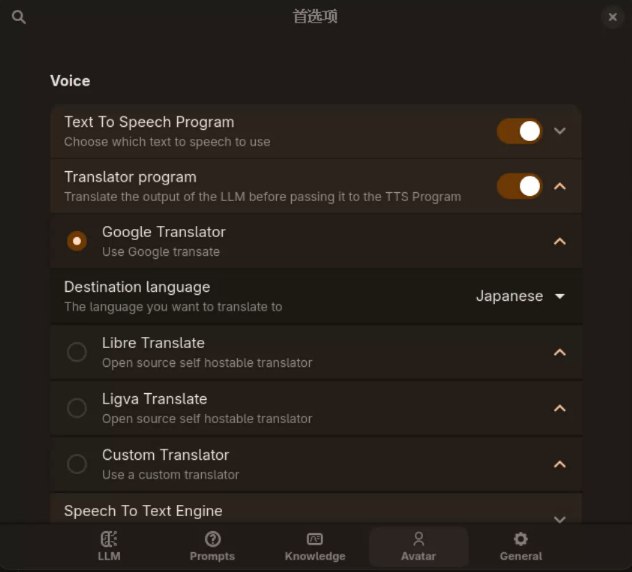
Since it only supports Japanese, if you don't know Japanese, you can decide to enable translations,enable the Translator program in Avatar and select Japanese as the translation language.
Installing and using VoiceVox
If you have Smart prompts enabled, you can ask Arch-chan to guide you through these steps! In case you don't trust her yapping, here are the full instructions.
Step 1: Install docker
sudo pacman -S docker
sudo systemctl enable --now docker
If you have a Nvidia GPU and you want to use it, also install nvidia-container-toolkit. Also, Nvidia proprietary drivers must be installed.
sudo pacman -S nvidia-container-toolkit
sudo systemctl restart docker.service
Step 2: Install the docker container
If you want to use CPU ONLY:
sudo docker pull voicevox/voicevox_engine:cpu-ubuntu20.04-latest
If you want to use Nvidia GPU:
sudo docker pull voicevox/voicevox_engine:nvidia-ubuntu20.04-latest
Step 3: Start the containter
If on cpu:
sudo docker run --rm -it -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:cpu-ubuntu20.04-latest
If on gpu:
sudo docker run --rm --gpus all -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:nvidia-ubuntu20.04-latest
You will have to start the container every time you want to use voicevox
Step 4: Configure it on Nyarch Assistant settings
Effect
Put http://localhost:50021 as endpoint (or the ip/port you chosen if you host it somewhere else).
Then, close and reopen the settings to reload the voices and then choose your favourite voice.
Voice Cloning
You can use this extension to do voice cloning with TTS.